Définition :
L'intelligence artificielle désigne une nouvelle classe d'algorithmes extrêmement puissants paramétrés à partir de techniques dite d'apprentissage automatique, ou machine learning. L'une des branches de cet apprentissage, l'apprentissage profond ou deep learning, est un processus où les instructions à exécuter ne sont plus programmées explicitement par un développeur humain, mais générées par la machine elle-même qui "apprend" à partir de bases de données gigantesques qui lui sont fournies.
Andrew Ng, de l'Université Stanford, définit le machine learning comme « la science permettant de faire agir les ordinateurs sans qu'ils aient à être explicitement programmés ».
(source : CNIL)
Le machine learning et le deep learning
1. Le machine learning ⚓
Le machine learning permet, à partir de données, de deviner une valeur inconnue. Le processus se déroule selon deux phases :
1. La phase d'apprentissage où la machine reçoit des données X et les apprend.
Une entrée X et une sortie Y sont présentées à un algorithme qui "tourne deux boutons a et b" jusqu'à ce qu'il ait compris le lien du type Y = aX + b entre X et Y.

2. La phase de prédiction, ou d'extrapolation, où la machine reconnaît une donnée brute.
Une fois les "boutons a et b" trouvés dans la relation Y = aX + b, la machine donne Y à partir de X.

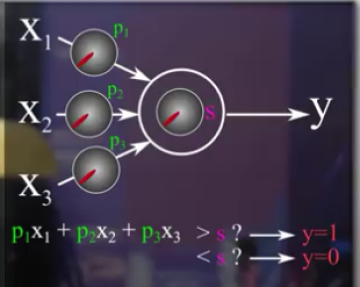
2. Le neurone artificiel⚓
Le neurone artificiel fonctionne comme un neurone biologique et joue le même rôle que la droite Y = aX + b :
il reçoit en entrée trois valeurs X1, X2 et X3 pondérées chacune d'un poids p1, p2 et p3,
si la somme pondérée dépasse un seuil S, la réponse est 1, sinon la réponse est 0.
3. Le réseau de neurones⚓
Pour établir des fonctions plus compliquées, les neurones sont empilés en réseau de neurones. Ces réseaux sont polyvalents et sont utilisés de la même façon que précédemment à l'aide d'une droite Y = aX + b.
Chacun des neurones du réseau cherche et trouve le lien entre les entrées et les sorties (phase d'apprentissage) et lorsqu'une donnée X est présentée à l'entrée, il trouve Y en sortie (phase de prédiction).
Seulement, lorsqu'il y a trop de neurones dans le réseau, la phase d'apprentissage devient impossible.

4. Le réseau de neurone avec couches intermédiaires⚓
Dans la pratique, la "machine" comporte :
une 1ère couche de neurones X1, X2, X3, X4, X5,
un neurone de sortie Y,
une (ou plusieurs) couche intermédiaire de neurones.
Plus le nombre de neurones est grand dans la couche intermédiaire, plus le réseau est polyvalent et puissant, mais difficile à "entraîner", particulièrement pour la reconnaissance d'images.

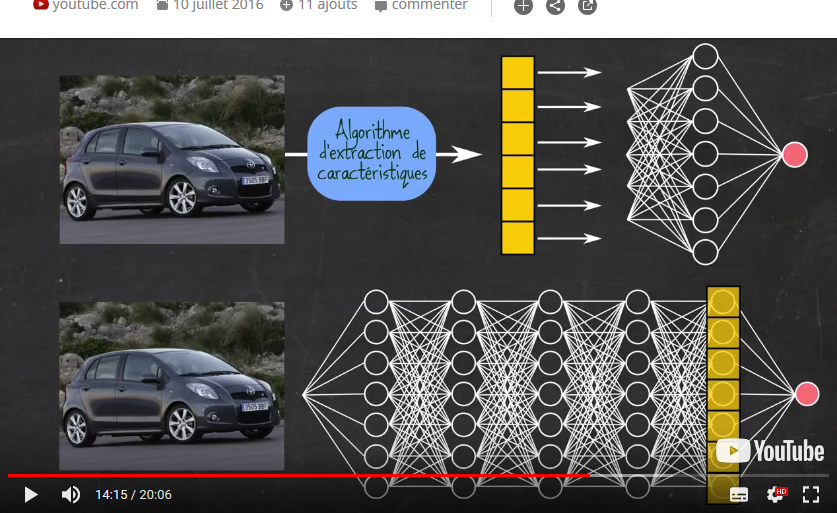
5. L'algorithme d'extraction de caractéristiques⚓
Un algorithme d'extraction de caractéristiques, qui n'est pas un réseau de neurones, analyse une images et en établit une liste des caractéristiques intéressantes, qui la résume en donnant une sorte d'abstraction.
Cette liste de caractéristiques est ensuite présentée à un réseau de neurones pour faire la reconnaissance d'images.
Ce processus a un avantage :
l'image brute contient plusieurs millions de pixels et la liste seulement quelques dizaines.
Mais il a aussi un inconvénient :
la qualité du résultat dépend du concepteur, pas forcément expert. D'où l'idée du deep learning.

6. Le deep learning⚓
L'idée a été de "sauter" l'étape de la liste de caractéristiques et de créer un "gros" réseau, avec une quantité énorme de neurones, à qui est présentée l'image brute : c'est le réseau profond.
Dans cette configuration, la phase d'apprentissage, en théorie, ne peut pas fonctionner. Sauf qu'en 2012, un chercheur français pionnier (Yann le Cun) réussit à le faire et ouvre en même temps une nouvelle voie à l'IA.
En entraînant le réseau correctement, les couches supérieures du réseau contiennent les caractéristiques essentielles : l'algorithme les a découvert lui-même sans que personne ait eu besoin de le faire pour lui.
7. Les raisons de l'émergence du deep learning⚓
Les raisons de l'émergence de ce processus réside dans plusieurs facteurs :
les progrès des algorithmes,
la puissance de calcul considérablement augmentée, notamment avec les cartes graphiques GPU,
la disponibilité des données avec les bases de données comme "Imagenet" (15 millions d'images classifiées).
Lorsqu'une telle base d'images est présentée à un algorithme de deep learning, il trouve tout seul les caractéristiques essentielles de cette base d'images.

8. Les autres applications du deep learning⚓
Le deep learning est introduit dans de très nombreuses tâches, devançant à chaque fois de très loin les modèles concurrents, même ceux issus de décennies de recherche spécifique, comme :
Le modèle génératif (lorsque le réseau est pris en sens inverse et qu'il reçoit en entrée une série de nombres, il produit une image inventée en sortie).
La description et la retranscription d'une scène d'une image.
La conduite autonome.
La fabrication d'images psychédéliques.
La traduction automatique.

9. Les limites du deep learning⚓
Le deep learning a démontré sa performance sur quelques tâches notamment de perception (identification et reconnaissance d'objets) ou de jeux de réflexion (jeu de Go) mais reste encore très loin du niveau humain sur les tâches avec une forte composante sémantique (compréhension d'une histoire). Il est aujourd'hui difficile de savoir si ces lacunes vont être comblées avec l'augmentation de la puissance de calcul et donc de la taille des modèles exploitables ou s'il présente des limites inhérentes qui l'empêcheront d'atteindre le but ultime de l'IA : créer une intelligence artificielle forte.